5.1.5. Frequency Distributions
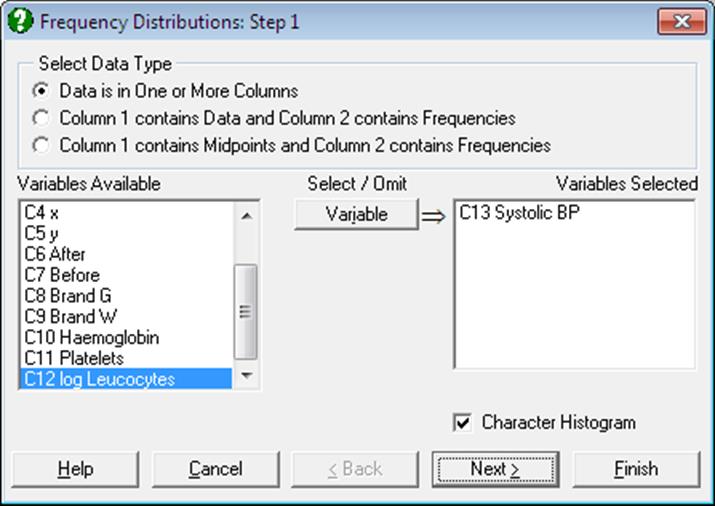
The Variable Selection Dialogue will offer three types of data to analyse (see 5.0.2. One-Sample Data Types). A check box situated at bottom right on the same dialogue will enable you to select the type of output: Frequency Table or Character Histogram.
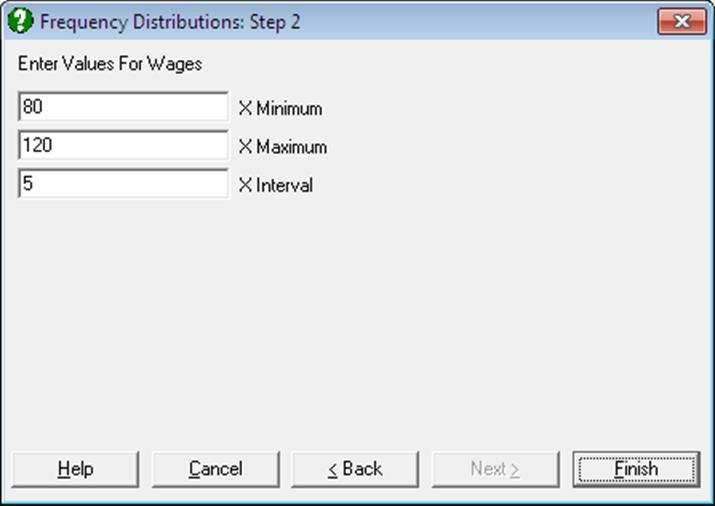
The next dialogue will prompt for the lower bound, upper bound and the class interval. The default values computed and suggested by the program will often generate a satisfactory outcome. However, the program’s suggestions can be overridden and other values used. If too small a class interval is entered the number of classes may turn out to be too large. By default, the program allows a maximum of 200 classes, though this can be increased if necessary. Also, if the specified lower limit is greater than the minimum observation or the upper limit is less than the maximum observation, then the cumulative and relative frequencies will not add up to their totals. In all three cases a message is issued, but the procedure is not aborted.
Starting from the lower bound, the program scans data in steps equal to the class interval and determines observations falling within each class. Class intervals are closed from below (or include the lower limit) and are open from above (or exclude the upper limit), with the exception of the last class, which is also closed from above. If the data is ungrouped (data option 1) then the program counts the number of observations within each class. If observations are accompanied with frequency counts (data option 2) then the program adds up the frequencies of observations falling within each class for a cumulative distribution. If the data is already grouped (data option 3) then the program will reconstruct all class midpoints according to the lower bound (the first observation) and the class interval (the difference between the second and the first observations) of column 1. No checks are made to determine whether the first column does actually contain midpoints.
Frequency Table: If the Table option is selected then the output will be in the form of a table containing class numbers, midpoints, frequency counts, cumulative frequency counts, percentages and cumulative percentages.
Character Histogram: A horizontal bar character histogram is drawn. The bar lengths are scaled so that the longest bar fits into the Width parameter defined in Tools → Options → Output → Text Margins.
Example 1
Open DEMODATA, select Statistics 1 → Descriptive Statistics → Frequency Distributions and from the Variable Selection Dialogue select the data option 1 Select Multiple Columns. Select Output 2 (C9) as [Variable] and accept the default values from the subsequent dialogues.
Frequency Distributions
For Output2
|
Class |
Mid-Point |
Frequency |
Cumulative |
Percentage |
Cumulative |
|
1 |
92.5000 |
5 |
5 |
8.6% |
8.6% |
|
2 |
95.0000 |
2 |
7 |
3.4% |
12.1% |
|
3 |
97.5000 |
2 |
9 |
3.4% |
15.5% |
|
4 |
100.0000 |
2 |
11 |
3.4% |
19.0% |
|
5 |
102.5000 |
3 |
14 |
5.2% |
24.1% |
|
6 |
105.0000 |
4 |
18 |
6.9% |
31.0% |
|
7 |
107.5000 |
7 |
25 |
12.1% |
43.1% |
|
8 |
110.0000 |
10 |
35 |
17.2% |
60.3% |
|
9 |
112.5000 |
17 |
52 |
29.3% |
89.7% |
|
10 |
115.0000 |
6 |
58 |
10.3% |
100.0% |
Example 2
Open DEMODATA, select Statistics 1 → Descriptive Statistics → Frequency Distributions and from the Variable Selection Dialogue select the data option 1 Select Multiple Columns. Select Output 2 (C9) as [Variable], check the Character Histogram box and accept the default values from the subsequent dialogues.
Frequency Distributions
For Output2
|
Class |
Mid-Point |
Frequency |
0.0000 17.0000 |
|
1 |
92.5000 |
5 |
****************** |
|
2 |
95.0000 |
2 |
******** |
|
3 |
97.5000 |
2 |
******** |
|
4 |
100.0000 |
2 |
******** |
|
5 |
102.5000 |
3 |
*********** |
|
6 |
105.0000 |
4 |
*************** |
|
7 |
107.5000 |
7 |
************************* |
|
8 |
110.0000 |
10 |
************************************ |
|
9 |
112.5000 |
17 |
************************************************************ |
|
10 |
115.0000 |
6 |
********************** |